Detailed evaluation methods
With your candidate models identified, it's time for thorough evaluation. This stage collects concrete evidence to support your embedding model selection through systematic testing of your specific use case.
Types of evaluation
Understanding two distinct evaluation approaches helps frame your testing strategy:
Model evaluation: Assesses the embedding model itself through direct metrics, typically using benchmarks or custom tasks matching your use case.
Downstream evaluation: Examines how the embedding model performs within your complete system (RAG pipeline, recommendation engine, etc.).
This lesson focuses on model evaluation to help you make initial selections while building AI-powered applications. We'll cover downstream evaluation in future courses.
Standard benchmarks
Standard benchmarks provide valuable reference points created by experts, often with readily available results requiring minimal effort to interpret.
Understanding MTEB in detail
The Massive Text Embedding Benchmark (MTEB) serves as an industry-standard measure, composed of over 100 individual tasks grouped by type:
- Retrieval: Finding relevant documents based on queries
- Classification: Categorizing text into predefined classes
- Clustering: Grouping similar texts together
- Reranking: Sorting results by relevance
- Semantic textual similarity (STS): Measuring semantic similarity between texts
Interpreting detailed MTEB scores
Rather than relying on overall scores, examine task-specific performance. MTEB's retrieval score combines results from 17 different benchmarks, revealing important nuances.
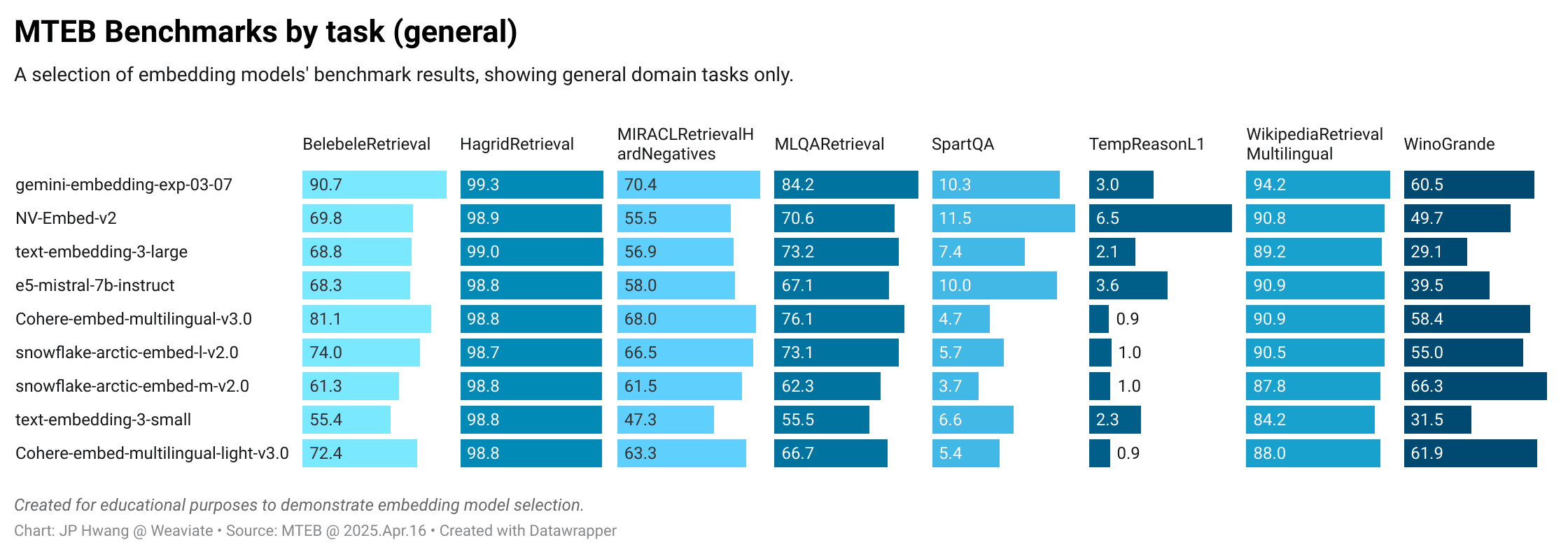
General domain tasks:
Specialized domain tasks:
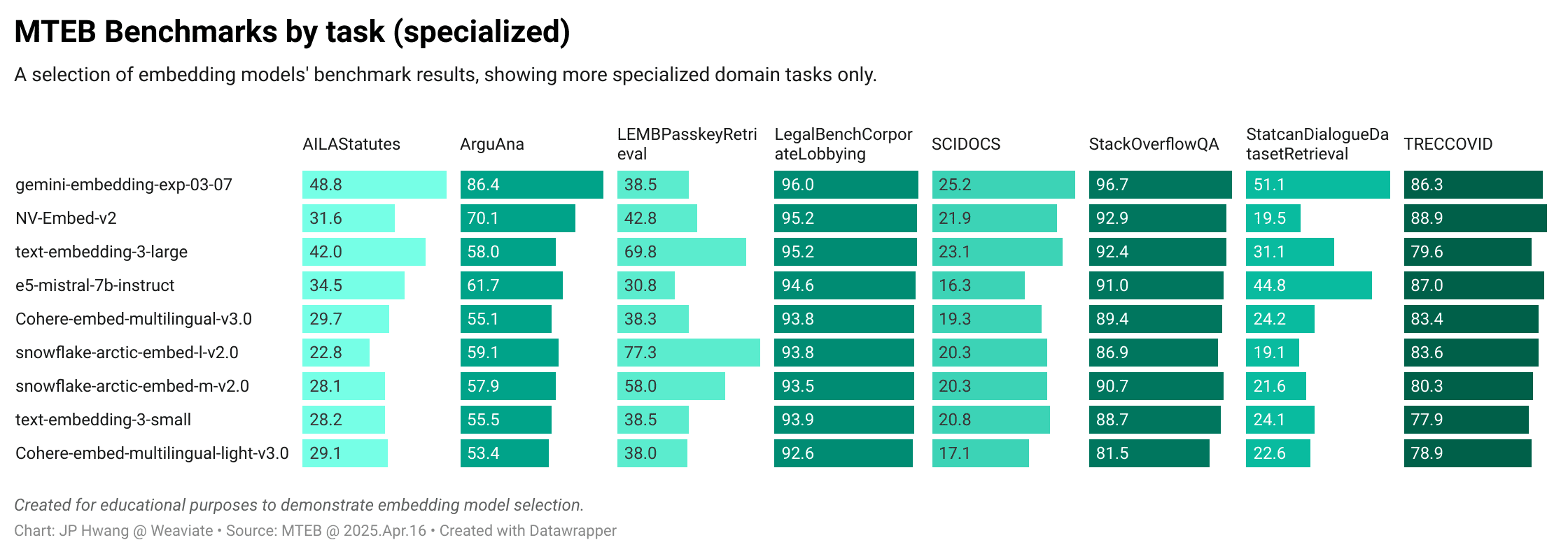
These charts reveal that while some models like gemini-embedding-exp-03-07 perform consistently well, others excel in specific areas:
- Snowflake Arctic models: Outstanding performance on
LEMBPasskeyRetrieval(finding specific text in long embeddings) - Cohere multilingual models: Excel on
MIRACLtasks (highly multilingual retrieval)
Creating custom benchmark weights
Standard MTEB scores may not reflect your priorities. Consider creating weighted scores based on:
- Task relevance: How closely does each task match your use case?
- Data distribution: Does the benchmark data represent your domain?
- Metric alignment: Do reported metrics align with your requirements?
- Language distribution: Does the language mix match your data?
For example, if your application requires strong multilingual support, weight multilingual tasks more heavily than English-only tasks.
Benchmark limitations
Data leakage risk: Public benchmarks may appear in model training data, inflating scores and creating unfair advantages.
Limited correlation: Standard benchmarks rarely perfectly align with your specific use case, data distribution, and success metrics.
Mitigation strategy: Use standard benchmarks as reference points while conducting custom evaluations for definitive model selection.
Custom benchmarks
Creating your own evaluation addresses standard benchmark limitations and provides use case-specific insights.
Setting benchmark objectives
Define clear goals addressing knowledge gaps, such as:
- "Which model best retrieves customer reviews about coffee in English, French, and Korean?"
- "How do models perform across Python/Golang code retrieval and related documentation?"
Determining appropriate metrics
For retrieval tasks, common metrics include:
- Precision: Percentage of retrieved items that are relevant
- Recall: Percentage of relevant items that were retrieved
- MAP (Mean Average Precision): Average precision across multiple queries
- MRR (Mean Reciprocal Rank): Average of reciprocal ranks of first relevant results
- NDCG (Normalized Discounted Cumulative Gain): Rewards high-relevance results at top positions
NDCG is often ideal as it rewards systems for correctly prioritizing highly relevant results.
Curating benchmark datasets
Effective datasets should:
- Reflect your retrieval task: Match query types and document characteristics
- Capture task difficulty: Include challenging cases that differentiate models
- Represent data distribution: Mirror your actual data (domain, language, length)
- Provide sufficient volume: Even 20 objects with multiple queries can yield meaningful results
Pragmatic approach: Start small but representative. Quality trumps quantity in custom benchmarks.
Running benchmarks systematically
Ensure reproducibility and consistency:
- Modularize components: Separate embedding creation, dataset loading, metric evaluation, and result presentation
- Document methodology: Record model versions, parameters, and evaluation procedures
- Control variables: Test models under identical conditions
- Plan for iteration: Structure code to accommodate new models and updated requirements
Comprehensive result evaluation
Quantitative analysis
Calculate definitive metrics like NDCG@k scores to rank models objectively. However, remember these rankings depend on dataset composition and chosen metrics.
Qualitative analysis
Often provides more actionable insights through pattern recognition:
Common failure patterns:
- Favoring longer documents over shorter, highly relevant ones
- Struggling with negation in sentences
- Poor handling of domain-specific terminology
- Language-specific performance variations (strong in English/Mandarin, weak in Hungarian)
Domain expertise advantage: Qualitative assessment often requires domain knowledge and system context, making it critically important for final decisions.
The combination of quantitative rankings and qualitative insights provides the complete picture needed for informed model selection.
Now let's see this evaluation process in action with a practical example that demonstrates how to design and execute custom benchmarks for technical documentation retrieval.