Identifying requirements across all dimensions
The foundation of successful embedding model selection is clearly identifying your requirements. This systematic approach ensures you consider all relevant factors when evaluating models.
Requirements framework
Organize your requirements into four key categories to ensure comprehensive coverage:
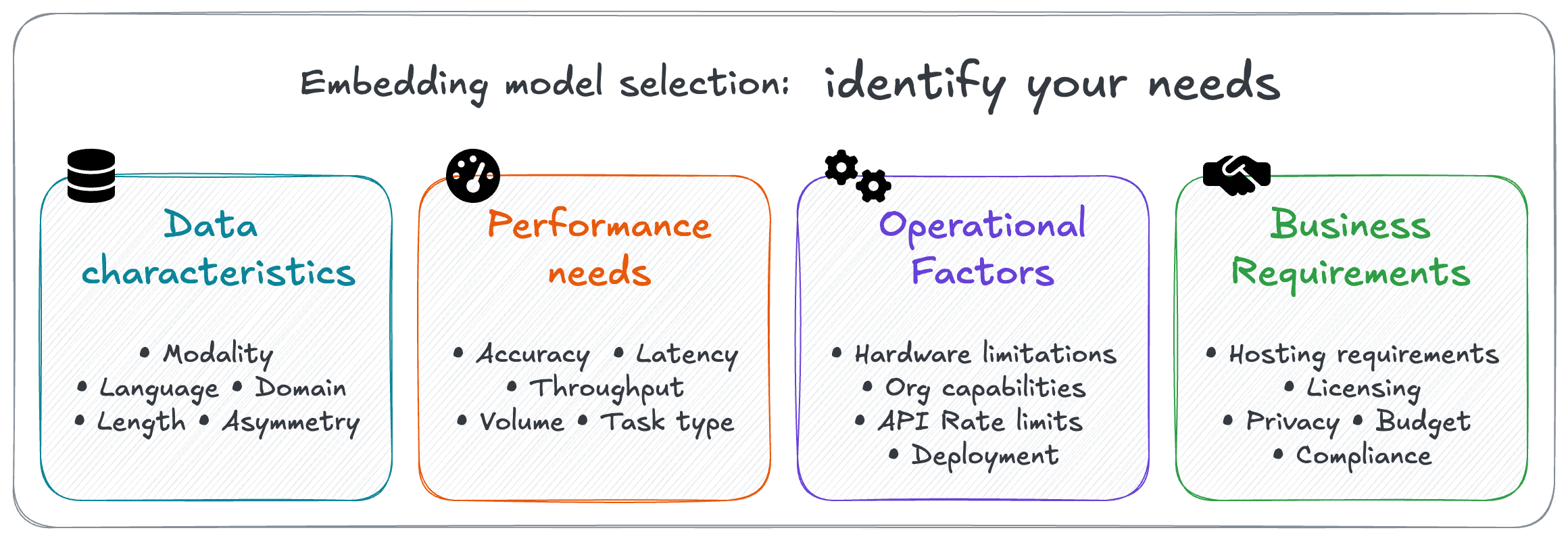
Data characteristics
Understanding your data is crucial since models are designed and optimized for specific characteristics.
| Factor | Key Questions | Why It Matters |
|---|---|---|
| Modality | Are you dealing with text, images, audio, or multimodal data? | Models are built for specific modalities. A text-only model cannot perform image retrieval. |
| Language | Which languages must be supported? | Models are trained for specific languages, leading to performance trade-offs. |
| Domain | Is your data general or domain-specific (legal, medical, technical)? | Domain-specific models understand specialized vocabulary and concepts better than general models. |
| Length | What's the typical length of your documents and queries? | Context windows vary from 256 to 8,192+ tokens. Longer contexts require exponentially more compute. |
| Asymmetry | Will your queries differ significantly from your documents? | Some models excel at asymmetric comparisons (short queries vs. long documents). |
Domain-specific considerations
For specialized domains, consider:
- Medical: Models trained on medical literature understand terminology like "myocardial infarction" vs. "heart attack"
- Legal: Legal models grasp concepts like precedent, jurisdiction, and contractual language
- Technical: Code and API documentation models understand programming concepts and syntax
Performance needs
Define your performance requirements to guide model selection and infrastructure planning.
| Factor | Key Questions | Why It Matters |
|---|---|---|
| Accuracy (recall) | How critical is retrieving all relevant results? | Higher accuracy may justify more expensive or resource-intensive models. |
| Latency | How quickly must queries be processed? | Larger models often have slower inference times. |
| Throughput | What query volume do you anticipate? | Higher throughput requirements affect model choice and infrastructure costs. |
| Volume | How many documents will you process? | Embedding dimensions impact memory requirements and scale costs. |
| Task type | Is retrieval the only use case, or will you need clustering/classification? | Models have different strengths; retrieval excellence doesn't guarantee clustering performance. |
Performance trade-offs
Consider these typical trade-offs:
- High accuracy + Low latency: May require expensive hardware or premium API tiers
- High throughput + Low cost: May require smaller, faster models with acceptable accuracy loss
- Large document volumes: Favor models with smaller embedding dimensions to manage memory costs
Operational factors
Assess your technical capabilities and constraints.
| Factor | Key Questions | Why It Matters |
|---|---|---|
| Hardware limitations | What computational resources are available? | GPU availability and memory constraints limit model options. |
| API rate limits | What are the provider's usage restrictions? | Rate limits can bottleneck applications or limit growth. |
| Deployment & maintenance | What expertise do you have for self-hosting vs. APIs? | Self-hosting requires ML ops expertise; APIs offer simplicity but create dependencies. |
Deployment models comparison
Self-hosting advantages:
- Full control over model and infrastructure
- No external API dependencies
- Potentially lower long-term costs at scale
- Data never leaves your infrastructure
API advantages:
- Lower technical complexity
- Immediate availability
- Provider handles updates and maintenance
- Pay-as-you-go scaling
Business requirements
Align technical choices with business constraints and strategic goals.
| Factor | Key Questions | Why It Matters |
|---|---|---|
| Hosting options | Do you need self-hosting, or is cloud API acceptable? | Affects control, complexity, and dependencies. |
| Licensing | What restrictions exist for commercial use? | Some licenses prohibit commercial applications or require attribution. |
| Long-term support | What guarantees exist for continued availability? | Model abandonment can require significant reworking of applications. |
| Budget | What are your cost limits and preferences? | Embedding costs accumulate; self-hosting has high upfront costs. |
| Privacy & compliance | Are there data privacy or regulatory requirements? | May dictate hosting requirements or specific model choices. |
Compliance considerations
Different industries have specific requirements:
- Healthcare: HIPAA compliance may require on-premises deployment
- Financial: Regulatory requirements may mandate specific model types
- Government: Security clearance levels may restrict model choices
- EU operations: GDPR may influence data processing and storage decisions
Documenting requirements
Create a requirements document that includes:
- Must-have criteria: Non-negotiable requirements (e.g., modality support, compliance needs)
- Performance targets: Specific metrics and thresholds (e.g., < 100ms latency, >0.85 accuracy)
- Preference ranking: Prioritized list of desired features
- Constraints: Budget limits, hardware restrictions, timeline constraints
- Success metrics: How you'll measure whether the chosen model meets your needs
This documentation becomes your evaluation framework and helps you make informed trade-offs between competing models.
With your requirements clearly defined, you're ready to compile a list of candidate models. We'll explore efficient screening techniques to identify the most promising options without getting overwhelmed by the hundreds of available models.