Vector index configuration
Different index types optimize for different scenarios. Memory usage is typically the biggest constraint when choosing vector indexes.
Index type selection
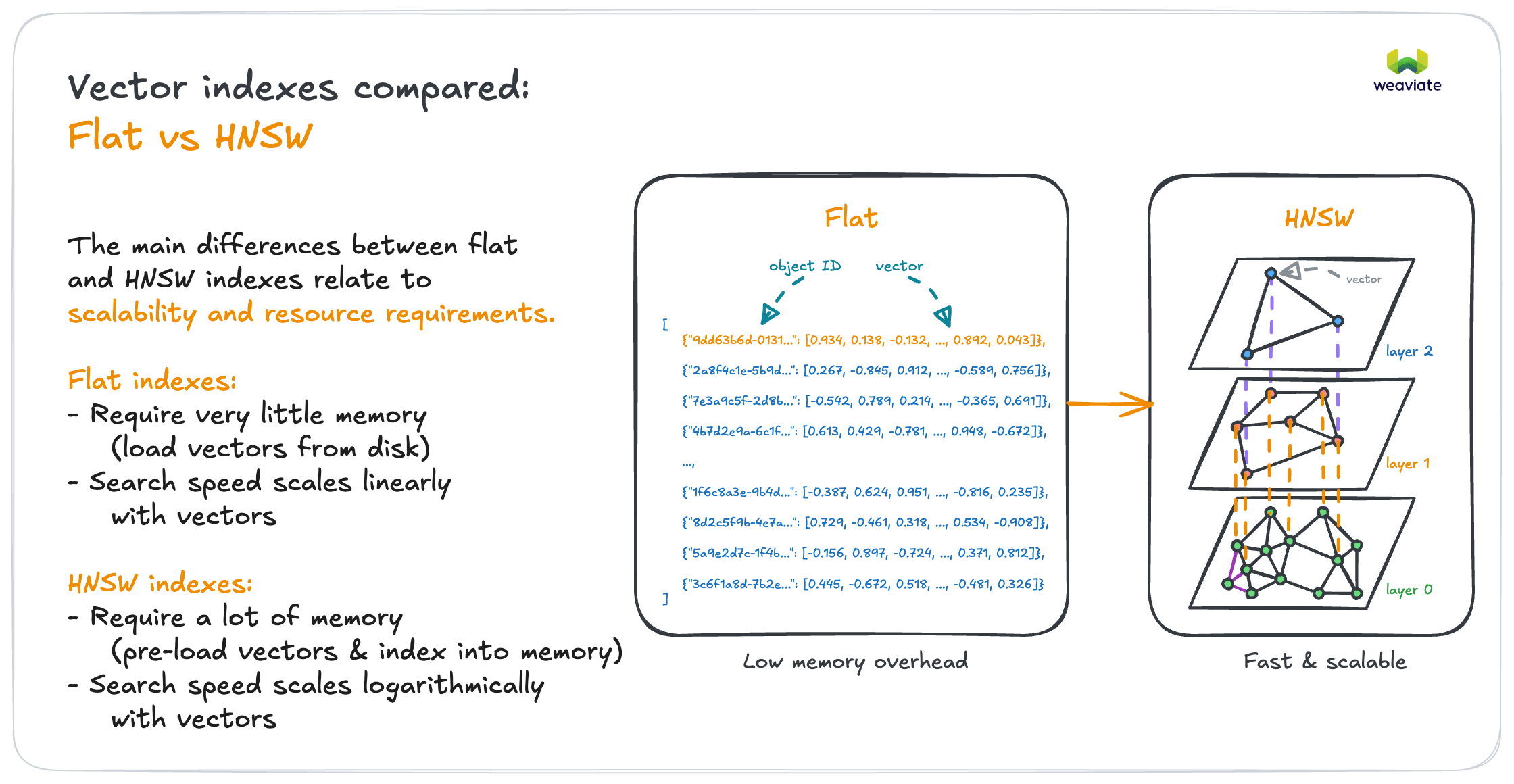
If < 100K objects → Flat index
- Perfect accuracy with acceptable search speed
- Little memory overhead for vectors
If > 100K objects with known size → HNSW index
- Scales logarithmically, to billions of vectors
- Balances speed and accuracy through tunable parameters
- Caches vectors in memory for fast access
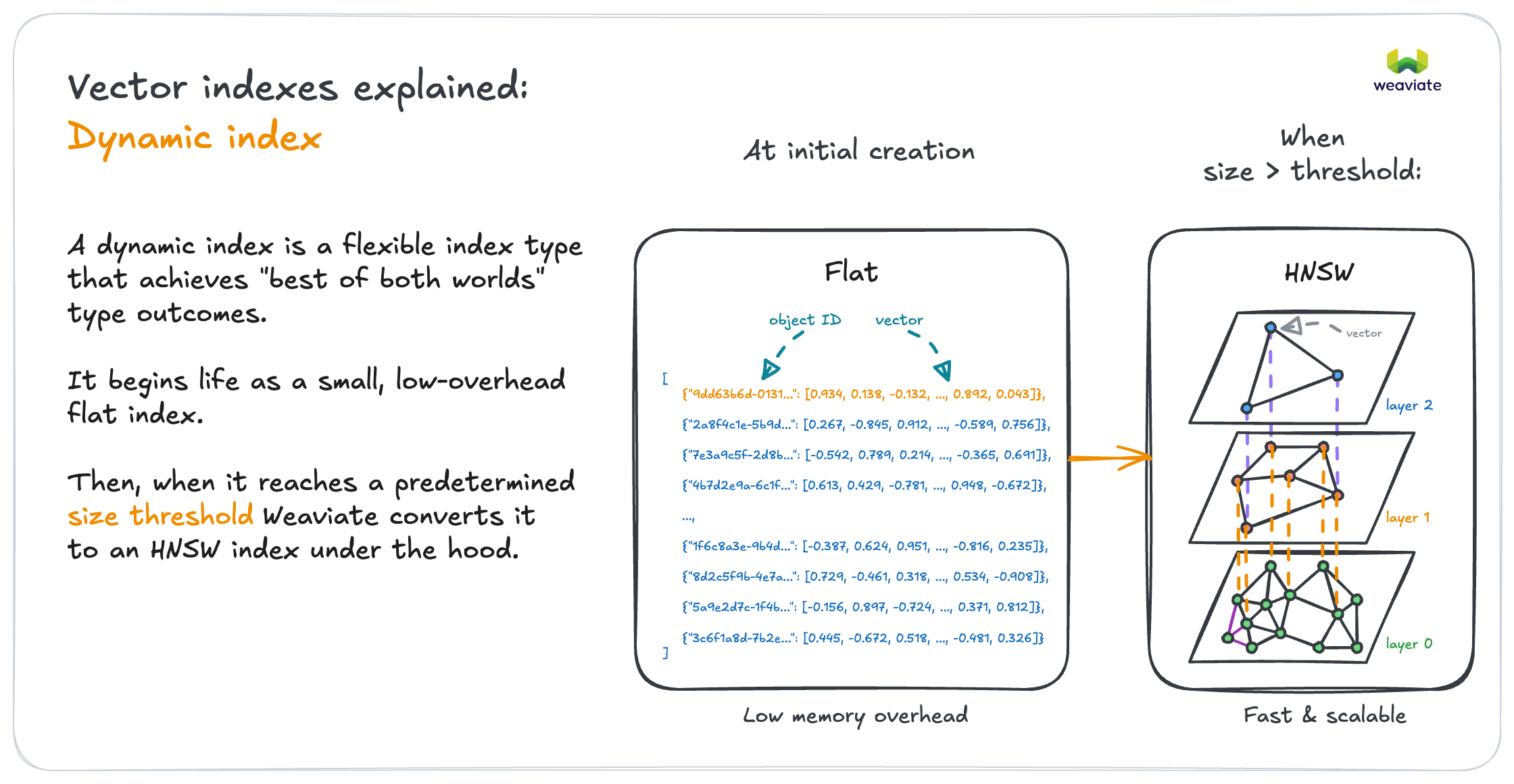
If multi-tenant with varying tenant sizes → Dynamic index
- Automatically switches between flat and HNSW per tenant
- Small tenants get flat (efficiency), large tenants get HNSW (speed)
Index planning example
Scenario: Multi-tenant document search
- 1000 tenants
- Tenant sizes: 10-100K documents each
- Growth expected
Recommendation: Dynamic index
- Small tenants (<10K docs): Flat index
- Large tenants (>50K docs): HNSW index
- Automatic transitions as tenants grow
Vector compression
Vector compression reduces memory usage at a slight cost to search quality. Weaviate stores original vectors, so you can always retrieve the uncompressed vectors.
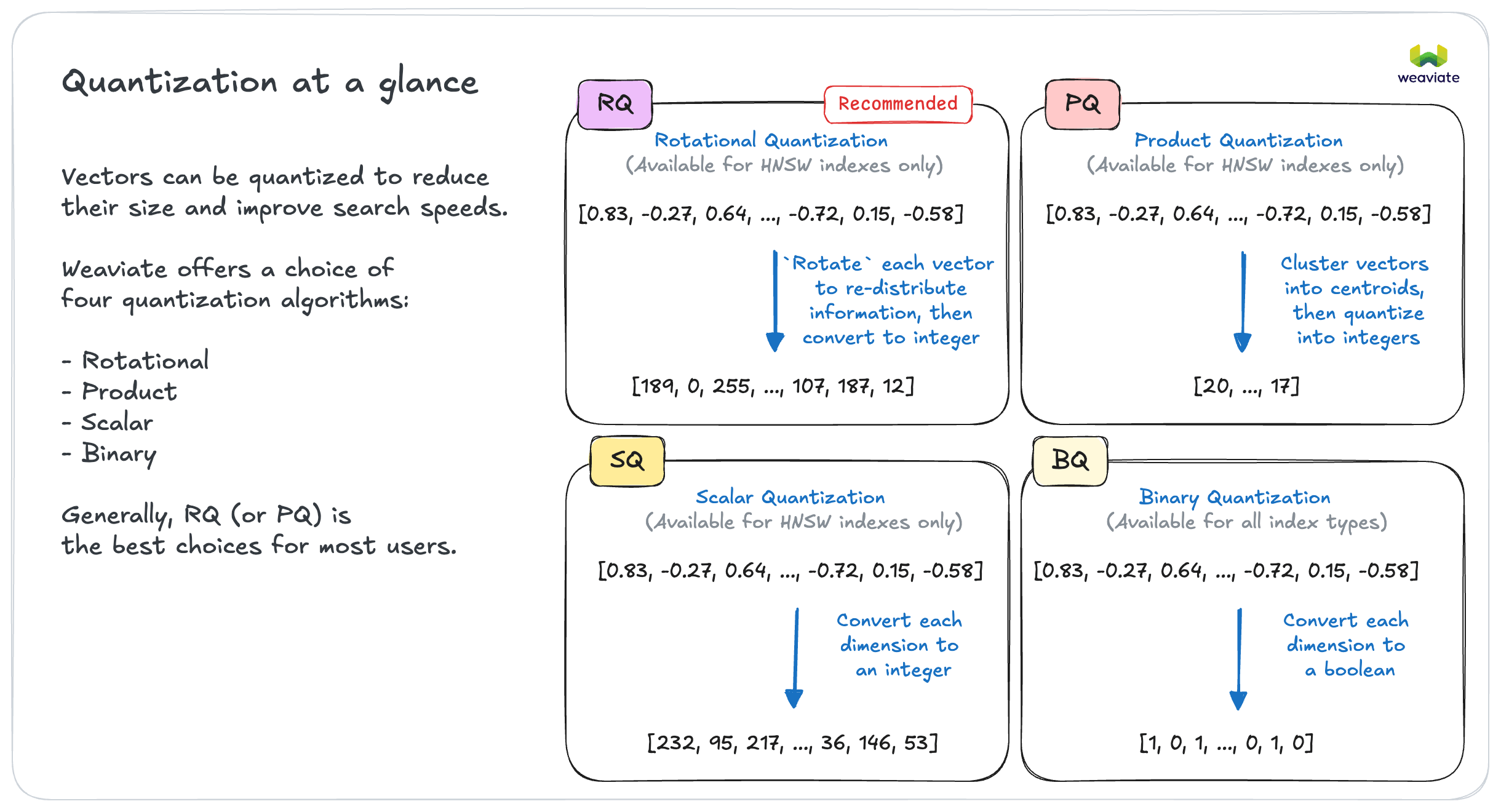
In most cases → Enable quantization
- Can reduce memory footprint significantly (e.g. by 75%) & therefore cost
- Throughput can improve also
- Start with rotational quantization for HNSW indexes
- Reduction in search quality is often negligible
If retrieval quality is critical → Test with/without quantization
- Some applications may be sensitive to compression artifacts
- Test end-to-end with your data and queries
If using multi-vector models (ColBERT) → Enable multi-vector encoding
- These models produce very large embeddings that benefit significantly from compression
Memory planning
HNSW vector indexes are the biggest memory consumer, caching vectors in memory for fast access.
Memory formula (vectors only): objects × vectors × dimensions × 4 bytes
Example calculations (uncompressed):
- 100K products × 1 vector × 1536 dims × 4 bytes = ~600MB
- 1M document chunks × 2 vectors × 768 dims × 4 bytes = ~3GB
If memory constrained → Use quantization + optimize dimensions
- Reduce dimensions: 1536 → 768
- Enable quantization: significant (e.g. 75%) memory reduction
Overall system requirements may be around ~2x that of the vectors only, although this varies.
Vector index tuning
HNSW indexes are highly tunable for your speed vs accuracy requirements.
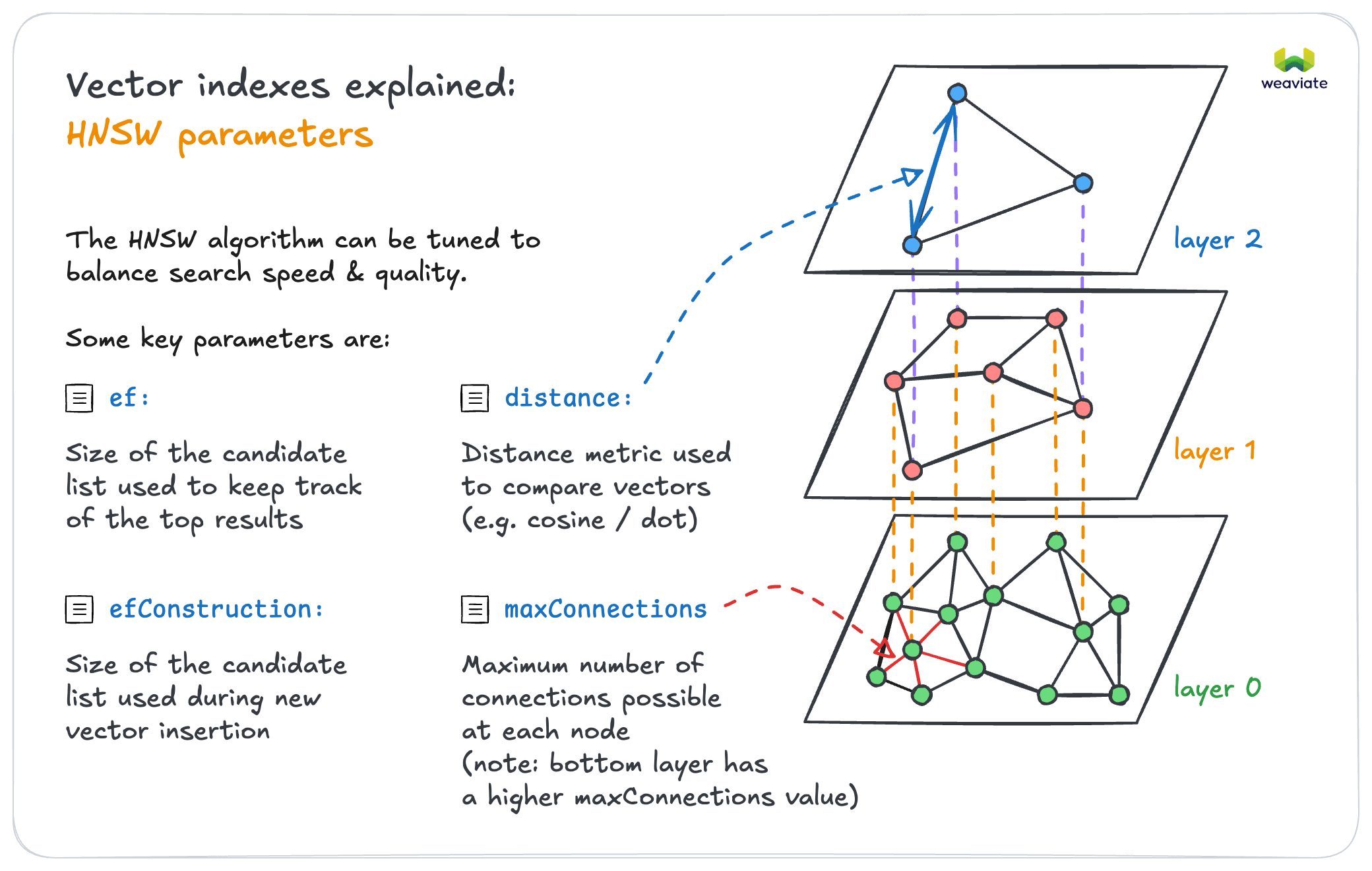
Performance Tuning
If speed matters more than perfect accuracy → Lower ef values
- Good for applications where speed is critical
If accuracy is critical → Higher ef values
- Good for applications where missing results is costly
If doing bulk imports → Lower efConstruction during import, increase for queries
- Speeds up initial data loading
- Increase ef for production query performance
In many cases, the defaults may be sufficient. Start with default values before tuning them.
Let's explore advanced patterns like collection aliases and multi-tenancy optimization that can make your deployment more flexible and efficient.